训练设备最佳效益分析模型
训练设备最佳效益分析模型
# 训练设备最佳效益分析模型
# 1. 说明
- 依据设备最佳效益的数据,训练出适用的分析模型并保存模型权重。
- 训练完成后,向FastWeb发送消息,更新设备最佳效益训练记录。
- 发送消息至FastWeb消息服务,提示模型训练完成。
# 2. 设计Python程序
设计的Python示例程序如下:
# 模型训练
import torch
import torch.nn as nn
import torch.optim as optim
import json
#import websockets
import requests
#from aiohttp import web
#from pydantic import BaseModel
import csv
import random
import datetime
#import asyncio
import os
import logging
from logging.handlers import TimedRotatingFileHandler
import sys
#import gc
fastweb_url = 'http://192.168.0.201:8803'
# 检测目录是否存在,如不存在则创建新目录
def create_directory_if_not_exists(directory_path):
if not os.path.exists(directory_path):
os.makedirs(directory_path)
#logger.info(f"目录 '{directory_path}' 创建成功!")
# 定义神经网络模型
class NeuralNetwork(nn.Module):
def __init__(self):
super(NeuralNetwork, self).__init__()
self.hidden_layers = nn.Sequential(
nn.Linear(4, 100),
nn.ReLU()
)
for _ in range(9):
self.hidden_layers.add_module(f'hidden_{_+1}', nn.Linear(100, 100))
self.hidden_layers.add_module(f'relu_{_+1}', nn.ReLU())
self.output_layer = nn.Linear(100, 1)
def forward(self, x):
x = self.hidden_layers(x)
x = self.output_layer(x)
return x.squeeze(-1)
# 定义损失函数
def huber_loss(input, target, delta):
residual = torch.abs(input - target)
condition = residual < delta
loss = torch.where(condition, 0.5 * residual ** 2, delta * (residual - 0.5 * delta))
return loss.mean()
# 检查是否可用GPU加速
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
#model_path = "model/model.pt"
# 加载训练好的模型
model = NeuralNetwork().to(device)
# 将数据集分割为训练集和验证集
def split_dataset(data, split_ratio):
random.shuffle(data)
split_index = int(len(data) * split_ratio)
train_data = data[:split_index]
validate_data = data[split_index:]
return train_data, validate_data
# 将数据保存为CSV文件
def save_dataset_to_csv(filename, data):
with open(filename, 'w', newline='') as csvfile:
writer = csv.writer(csvfile)
writer.writerow(['kp', 'ki', 'kd', 'setpoint', 'sumWeight'])
writer.writerows(data)
# 加载数据集
def load_dataset_from_csv(filename):
data = []
with open(filename, 'r') as csvfile:
reader = csv.reader(csvfile)
next(reader) # 跳过标题行
for row in reader:
data.append([float(value) for value in row])
return data
# 训练数据
# 发起请求获取数据集
def main():
# 配置日志
logger = logging.getLogger('__dcc_pid_train__')
if logger.hasHandlers():
logger.handlers.clear()
# 配置日志
log_filename = 'log/dcc_pid_train.log'
log_formatter = logging.Formatter('%(asctime)s - %(levelname)s - %(message)s')
log_handler = TimedRotatingFileHandler(log_filename, when="D", interval=1, backupCount=7)
log_handler.suffix = "%Y-%m-%d.log"
log_handler.encoding = "utf-8"
log_handler.setFormatter(log_formatter)
# 创建日志记录器
logger = logging.getLogger('__dcc_pid_train__')
logger.setLevel(logging.DEBUG)
logger.addHandler(log_handler)
# 获取当前日期和时间
current_datetime = datetime.datetime.now()
# 根据日期和时间生成自动编号
# 这里使用年月日时分秒作为编号,例如:20230515120000
auto_number = current_datetime.strftime("%Y%m%d%H%M%S")
create_directory_if_not_exists('log/')
create_directory_if_not_exists('data/')
create_directory_if_not_exists('model/')
try:
params = json.loads(input_value.value)
# params = {'username':'admin','tag':'0','guid':'333','eqname':'esp32','periodid':'1','lr':0.001, 'weight_decay':0, 'lambda':0,'num_epochs':1000, 'batch_size':32}
url = fastweb_url
guid = params["guid"]
# 重新定义查询参数
query_params = {
'restapi': 'pid_energy_efficiency',
'eqname': params["eqname"],
'periodid': params["periodid"]
}
response = requests.get(url, params=query_params)
data = response.json()
dataset = []
for item in data["tabledata"]:
dataset.append([item['kp'], item['ki'], item['kd'], item['setpoint'], item['sumWeight']])
# 将数据集分割为训练集和验证集
train_data, validate_data = split_dataset(dataset, split_ratio=0.9)
#logger.info('split data')
# 保存训练集和验证集为CSV文件
save_dataset_to_csv(f'data/train_{params["eqname"]}_{auto_number}.csv', train_data)
save_dataset_to_csv(f'data/validate_{params["eqname"]}_{auto_number}.csv', validate_data)
# 加载训练集和验证集数据
train_data = load_dataset_from_csv(f'data/train_{params["eqname"]}_{auto_number}.csv')
validate_data = load_dataset_from_csv(f'data/validate_{params["eqname"]}_{auto_number}.csv')
# 转换数据为张量并移至GPU
train_X = torch.tensor([row[:-1] for row in train_data], dtype=torch.float32).to(device)
train_y = torch.tensor([row[-1] for row in train_data], dtype=torch.float32).to(device)
validate_X = torch.tensor([row[:-1] for row in validate_data], dtype=torch.float32).to(device)
validate_y = torch.tensor([row[-1] for row in validate_data], dtype=torch.float32).to(device)
# 创建神经网络实例
model_train = NeuralNetwork()
# 检查是否可用GPU加速
model_train.to(device)
# 设置训练参数
num_epochs = params['num_epochs']
batch_size = params['batch_size']
# 设置早停参数
early_stop_threshold = 0.001 # 阈值,当验证集损失上升超过该阈值时触发早停
early_stop_patience = 5 # 连续几个周期损失上升时触发早停
# 进行训练
best_validate_loss = float('inf')
patience_counter = 0 # 计数器,记录连续上升的周期数
#logger.info(params['lr'])
# 定义优化器
#optimizer = optim.Adam(model_train.parameters(), lr=params['lr'])
optimizer = optim.SGD(model_train.parameters(), lr=params['lr'])
criterion = huber_loss
# regularizer = torch.nn.L1Loss(reduction='mean')
# 进行训练
for epoch in range(num_epochs):
for i in range(0, train_X.shape[0], batch_size):
# 获取当前批次数据
inputs = train_X[i:i+batch_size]
targets = train_y[i:i+batch_size]
# 前向传播
outputs = model_train(inputs)
loss = criterion(outputs, targets, 0.1)
# 反向传播和优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 每隔一段时间输出当前的训练集损失值和验证集损失值
if (epoch+1) % 100 == 0:
train_loss = criterion(model_train(train_X), train_y, 0.1)
validate_loss = criterion(model_train(validate_X), validate_y, 0.1)
logger.info(f'Epoch [{epoch+1}/{num_epochs}], Train Loss: {train_loss.item()}, Validate Loss: {validate_loss.item()}')
# 检查验证集损失是否上升超过阈值
if validate_loss > best_validate_loss + early_stop_threshold:
patience_counter += 1
else:
patience_counter = 0
best_validate_loss = validate_loss
# 检查是否触发早停
if patience_counter >= early_stop_patience:
logger.info('Early stopping triggered. Training stopped.')
break
# 检查最终训练集损失值和验证集损失值
final_train_loss = criterion(model_train(train_X), train_y, 0.1)
final_validate_loss = criterion(model_train(validate_X), validate_y, 0.1)
logger.info(f'Final Train Loss: {final_train_loss.item()}, Final Validate Loss: {final_validate_loss.item()}')
ismodel = False
if final_validate_loss.item() < 1:
# 保存模型
model_path = f"model/{params['eqname']}_{auto_number}.pt" # 保存的模型文件路径
torch.save(model_train.state_dict(), model_path)
logger.info("模型已保存")
ismodel = True
# 更新训练记录
isfinish = True
url = fastweb_url + "/?restapi=pid_update_trainlog"
data = {"guid":guid,"lr":params['lr'],"num_epochs":params['num_epochs'],"batch_size":params['batch_size'],"train_loss":final_train_loss.item(),"validate_loss":final_validate_loss.item(),"isfinish":isfinish,"ismodel":ismodel,"model_path":model_path}
data = json.dumps(data)
logger.info(data)
response = requests.post(url, data=data)
if response.status_code == 200:
logger.info("请求成功")
# 可以使用http呼叫FastWeb,提示已经完成相关工作
# 删除生成的临时文件
os.remove(f'data/train_{params["eqname"]}_{auto_number}.csv')
os.remove(f'data/validate_{params["eqname"]}_{auto_number}.csv')
# 呼叫http 提示已训练完成
data = json.dumps({"username":params['username'],"action":"callback","tag":params['tag'], \
"data":{"callbackcomponent":"WebHomeFrame","callbackeventname":"update", \
"callbackparams":[{"paramname":"messagetype","paramvalue":"success"},{"paramname":"title","paramvalue":"success"},{"paramname":"message","paramvalue":"设备最佳运转效益模型训练已完成"}]}})
input_value.value = '训练已完成'
url = fastweb_url + "/?restapi=sendwsmsg"
response = requests.post(url, data=data)
if response.status_code == 200:
logger.info("请求成功")
# 保留的系统变量列表(如 __name__ 等)
keep = {'__name__', '__doc__', '__package__', '__loader__', '__spec__', '__builtins__'}
# 遍历全局变量并删除非保留项
for name in list(globals().keys()):
if name not in keep:
del globals()[name]
except Exception as e:
logger.error(e)
if __name__ == "__main__":
main()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
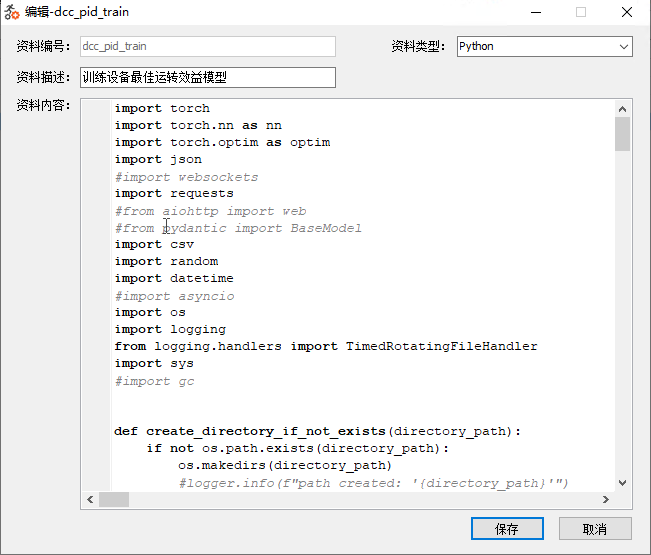
将上述程序保存为预设资料。按照下述样式进行保存。
上述程序中定义的参数说明如下:
- 参数名称:
input_value。
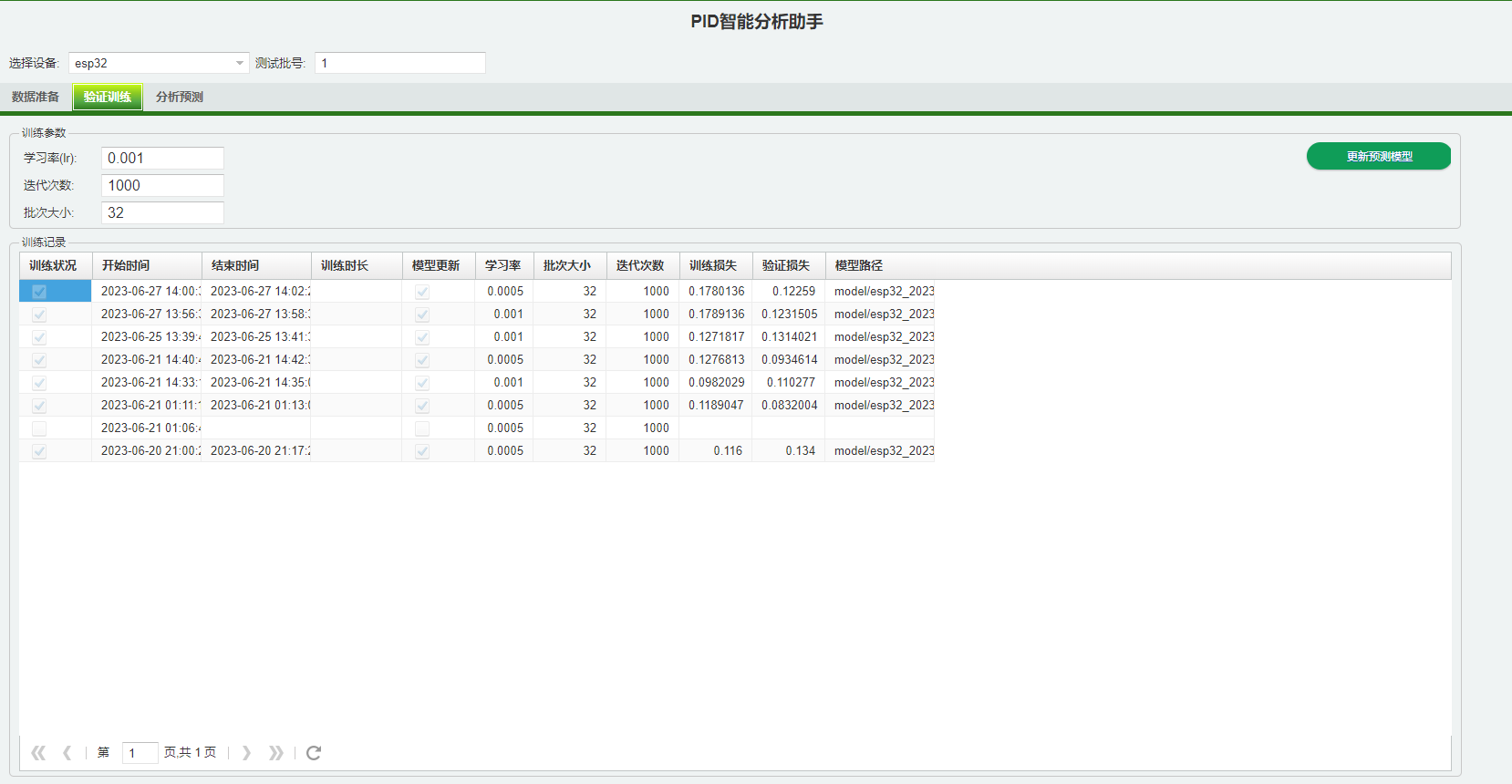
# 3. 调用执行
可以使用FastWeb 数控中心-设备最佳运转效益-PID智能分析助手 (opens new window)来呼叫启用模型分析的Python脚本。设置好调用taskrunner的地址,在验证训练界面点击[更新预测模型],以启用模型训练的过程。训练完成后,可以看到此次训练的记录,以及相关的训练结果。