训练设备故障诊断模型
训练设备故障诊断模型
# 训练设备故障诊断模型
# 1. 说明
- 依据设备故障诊断数据,训练出适用的分析模型并保存模型权重。
- 训练完成后,向FastWeb发送消息,更新设备故障诊断训练记录。
- 发送消息至FastWeb消息服务,提示模型训练完成。
# 2. 设计Python程序
设计的Python示例程序如下:
# 训练预测的模型
import torch
import datetime
import numpy as np
import torch.nn as nn
import torch.optim as optim
import pandas as pd
from sklearn.model_selection import train_test_split
from torch.utils.data import DataLoader, TensorDataset
import os
import logging
import json
from logging.handlers import TimedRotatingFileHandler
import requests
fastweb_url='http://192.168.0.201:8803'
# 检查文件夹是否存在,否则创建文件夹
def check_create_directory(path: str):
if not os.path.exists(path):
os.makedirs(path)
# 配置日志
check_create_directory('log/')
logger = logging.getLogger('__dig_train_model__')
if logger.hasHandlers():
logger.handlers.clear()
log_filename = 'log/dcc_dig_train.log'
log_formatter = logging.Formatter('%(asctime)s - %(levelname)s - %(message)s')
log_handler = TimedRotatingFileHandler(log_filename, when='D', interval=1, backupCount=30, encoding='utf-8')
log_handler.suffix = '%Y-%m-%d.log'
log_handler.encoding = 'utf-8'
log_handler.setFormatter(log_formatter)
# 创建日志记录器
logger = logging.getLogger('__dig_train_model__')
logger.setLevel(logging.DEBUG)
logger.addHandler(log_handler)
# 定义神经网络模型
class MLP(nn.Module):
def __init__(self):
super(MLP, self).__init__()
self.fc1 = nn.Linear(10, 100) # 10个输入参数,10个隐藏层
self.fc2 = nn.Linear(100, 100)
self.fc3 = nn.Linear(100, 100)
self.fc4 = nn.Linear(100, 100)
self.fc5 = nn.Linear(100, 100)
self.fc6 = nn.Linear(100, 100)
self.fc7 = nn.Linear(100, 100)
self.fc8 = nn.Linear(100, 100)
self.fc9 = nn.Linear(100, 100)
self.fc10 = nn.Linear(100, 9) # 9个输出层
def forward(self, x):
x = torch.relu(self.fc1(x))
x = torch.relu(self.fc2(x))
x = torch.relu(self.fc3(x))
x = torch.relu(self.fc4(x))
x = torch.relu(self.fc5(x))
x = torch.relu(self.fc6(x))
x = torch.relu(self.fc7(x))
x = torch.relu(self.fc8(x))
x = torch.relu(self.fc9(x))
x = self.fc10(x)
return x
def train_model(eqcode,data):
# 创建模型实例
model = MLP()
data = np.array(data)
data = pd.DataFrame(data)
# 提取特征和标签列
X = data.iloc[:, :10].values # 输入特征,假设有10个输入参数
y = data.iloc[:, 10:].values # 输出标签,假设有9个输出层
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.1, random_state=37)
# 随机打乱训练集
indices = list(range(len(X_train)))
shuffle_indices = torch.randperm(len(X_train))
X_train = X_train[shuffle_indices]
y_train = y_train[shuffle_indices]
# 转换为PyTorch张量
X_train = torch.Tensor(X_train)
y_train = torch.Tensor(y_train)
X_test = torch.Tensor(X_test)
y_test = torch.Tensor(y_test)
# 创建数据加载器
train_dataset = TensorDataset(X_train, y_train)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
# 定义损失函数和优化器
criterion = nn.MSELoss() # 使用均方误差损失
optimizer = optim.Adam(model.parameters(), lr=0.0009) # 使用Adam优化器
# 训练模型
num_epochs = 100
for epoch in range(num_epochs):
for inputs, labels in train_loader:
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
if (epoch+1) % 10 == 0:
logger.info(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.6f}')
# 保存模型到文件
check_create_directory('model/')
# 获取当前日期和时间
current_datetime = datetime.datetime.now()
# 根据日期和时间生成自动编号
# 这里使用年月日时分秒作为编号,例如:20230515120000
auto_number = current_datetime.strftime("%Y%m%d%H%M%S")
model_path = f"model/{eqcode}_dig_{auto_number}.pt" # 保存的模型文件路径
torch.save(model.state_dict(), model_path)
logger.info("模型已保存")
ismodel = True
isfinish = True
# 加载模型
loaded_model = MLP()
loaded_model.load_state_dict(torch.load(model_path))
# 在测试集上评估模型
loaded_model.eval()
with torch.no_grad():
test_outputs = loaded_model(X_test)
test_loss = criterion(test_outputs, y_test)
logger.info(f'Test Loss: {test_loss.item():.6f}')
return ismodel,isfinish,model_path,loss.item(),test_loss.item()
def main():
# params = {"username":"admin","tag":0,"guid": "98C99147-B84F-4BB6-9E4E-509F837A66E9 ","eqcode":"0103","lr":0.0001,"num_epochs":100,"batch_size":32}
params = json.loads(input_value.value)
# 一些主场景使用的功能,根据发送的数据,更新执行训练
if 'username' in params and 'tag' in params and 'guid' in params and 'eqcode' in params and 'lr' in params and 'num_epochs' in params and 'batch_size' in params:
guid = params['guid']
eqcode = params['eqcode']
lr = params['lr']
num_epochs = params['num_epochs']
batch_size = params['batch_size']
# 重新定义查询参数
query_params = {
'restapi': 'dig_ai_diagnosedata',
'eqcode': eqcode,
}
response = requests.get(url=fastweb_url, params=query_params)
data = response.json()
dataset = []
for item in data["tabledata"]:
dataset.append([item['vamp05'], item['vamp1'], item['vamp15'], item['vamp2'], item['vamp3'],\
item['vamp4'], item['vamp5'], item['vamp6'], item['acc1khz'], item['acc10khz'],\
0,0,0,0,0,0,int(item['isunbalance']),int(item['isuncenter']),int(item['isloose'])])
# 训练模型
ismodel,isfinish,model_path,train_loss,validate_loss = train_model(eqcode=eqcode,data=dataset)
# 更新训练记录
data = {"guid":guid,"lr":lr,"num_epochs":num_epochs,"batch_size":batch_size,"train_loss":train_loss,\
"validate_loss":validate_loss,"isfinish":isfinish,"ismodel":ismodel,"model_path":model_path}
data = json.dumps(data)
query_params={
'restapi': 'dig_ai_updatediagnosetrainlog'
}
response = requests.post(url=fastweb_url,params=query_params,data=data)
if response.status_code == 200:
logger.info(f'{response.content}')
logger.info("训练记录提交成功")
query_params={
'restapi': 'sendwsmsg'
}
data = json.dumps({"username":params['username'],"action":"callback","tag":params['tag'], \
"data":{"callbackcomponent":"WebHomeFrame","callbackeventname":"update", \
"callbackparams":[{"paramname":"messagetype","paramvalue":"success"},{"paramname":"title","paramvalue":"success"},\
{"paramname":"message","paramvalue":f"模型训练完成:{model_path}"}]}})
requests.post(url=fastweb_url,params=query_params,data=data)
data = json.dumps({"username":params['username'],"action":"callback","tag":params['tag'], \
"data":{"callbackcomponent":"W-EQ-MOD-2308-2","callbackeventname":"update", \
"callbackparams":[{"paramname":"refresh","paramvalue":"true"}]}})
requests.post(url=fastweb_url,params=query_params,data=data)
if __name__ == "__main__":
main()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
将上述程序保存为预设资料。按照下述样式进行保存。
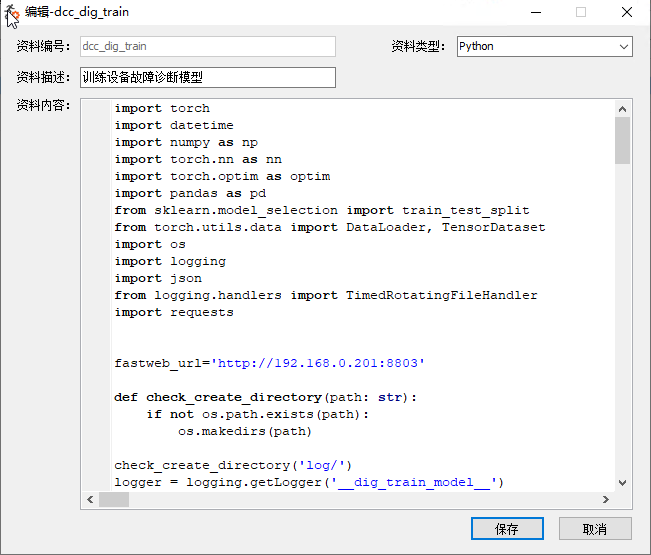
上述程序中定义的参数说明如下:
- 参数名称:
input_value。
# 3. 调用执行
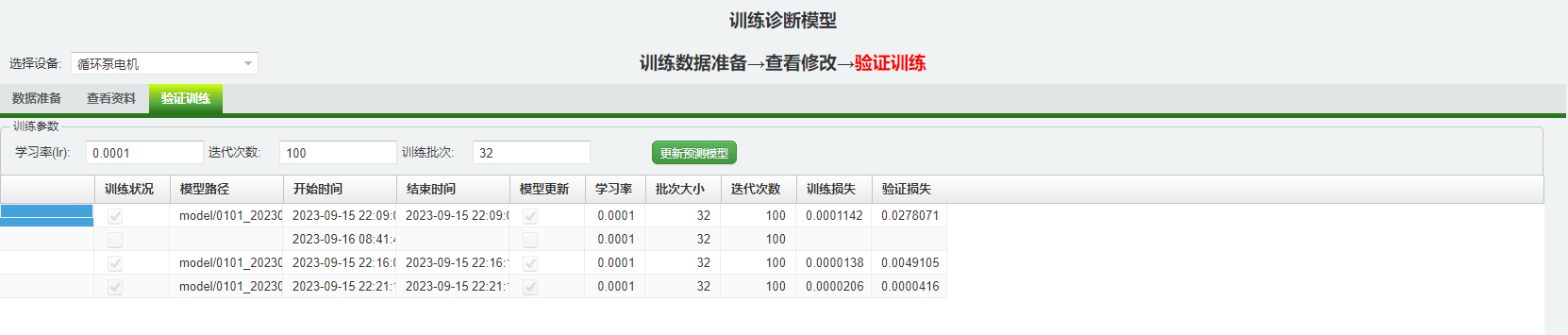
可以使用FastWeb 数控中心-设备故障诊断-训练诊断模型 (opens new window)来呼叫启用模型分析的Python脚本。设置好调用taskrunner的地址,在验证训练界面点击[更新预测模型],以启用模型训练的过程。训练完成后,可以看到此次训练的记录。